
Dieser Blogpost ist eine zugängliche Fassung meiner Seminararbeit über die architektonische Entwicklung von Googles Tensor Processing Units (TPUs). Auf Basis von peer-reviewter Forschung und offizieller technischer Dokumentation zeigt er, wie Google das Design von KI-Hardware über drei Generationen domänenspezifischer Beschleuniger verändert hat.
Kurzfassung
Google baute TPUs, um für matrixlastige ML-Workloads vorhersagbare, energieeffiziente Performance zu liefern, wo CPUs und GPUs an Grenzen stießen. Die Architektur entwickelte sich von INT8-Inferenz in v1 über bfloat16-Training mit v2/v3 bis zu v4+ mit HBM, großen Pods, eigenen Interconnects und Beschleunigern für Sparsity. Wenn du im großen Maßstab trainierst oder latenzsensitive Modelle auslieferst, können TPUs starken Durchsatz und gute Performance pro Watt bieten.
Der Auslöser: Als General-Purpose-Hardware an ihre Grenzen kam
2013 lieferte Googles Capacity-Planning-Team eine ernüchternde Prognose: Wenn jeder Android-Nutzer täglich nur drei Minuten Spracherkennung verwenden würde, müsste das Unternehmen seine gesamte Datacenter-Infrastruktur verdoppeln. Das war nicht nur ein Skalierungsproblem, sondern eine wirtschaftliche und ökologische Krise im Entstehen.
Das Grundproblem lag im fundamentalen Missverhältnis zwischen KI-Workloads und General-Purpose-Hardware. Neural-Network-Inferenz wird von dichten Matrixmultiplikationen dominiert, aber CPUs und selbst GPUs wurden für Flexibilität gebaut, nicht für maximale Effizienz bei genau dieser Aufgabe. Als Google NVIDIAs K80-GPU unter realen Bedingungen mit Antwortzeit-Anforderungen unter 10 ms testete, war sie nur minimal besser als eine CPU, weil die strengen Latenzgrenzen effektives Request-Batching verhinderten.
Die Eigenschaften, die CPUs und GPUs für allgemeine Workloads stark machen, tiefe Caches, komplexe Instruction Pipelines und ausgefeilte Branch Prediction, waren für vorhersagbare, matrixlastige KI-Inferenz-Aufgaben eher kontraproduktiv.
Diese Erkenntnis führte zu Googles mutiger Entscheidung, eigenes Silicon speziell für Neural-Network-Operationen zu entwickeln. Das Ziel war ambitioniert: 10x bessere Cost-Performance als GPUs bei gleichzeitig strengen Latenzanforderungen. Der Zeitplan war genauso aggressiv: nur 15 Monate vom Projektstart bis zum Einsatz im Datacenter.
TPU v1: Inferenz-Beschleunigung neu gedacht
TPU v1 erschien 2015 und war ein radikaler Bruch mit klassischem Prozessordesign. Statt allgemeine Flexibilität anzustreben, konzentrierten sich Googles Ingenieure konsequent auf die Operationen, die für Neural-Network-Inferenz am wichtigsten sind.
Architekturphilosophie: Einfachheit und Determinismus
Der Entwicklungszeitraum von 15 Monaten erzwang wichtige Designentscheidungen, die später zu den größten Stärken von TPU v1 wurden. Statt komplexer Out-of-Order-Execution oder ausgefeilter Cache-Hierarchien wählte das Team vorhersagbare, softwaregesteuerte Dataflow-Muster, die konstante Performance unter strikten Latenzanforderungen garantieren konnten.
TPU v1 wurde als PCIe-Gen3-x16-Coprozessorkarte umgesetzt und konnte dadurch ohne große Datacenter-Umbauten in bestehende Server-Infrastruktur integriert werden. Die Host-CPU kompilierte ganze Neural-Network-Inferenz-Graphen in Instruktionssequenzen und streamte sie zur TPU, die sie anschließend autonom mit minimalem weiteren Eingriff ausführte.
Das Herz der Maschine: Systolic-Array-Architektur
Im Kern von TPU v1 liegt ein 256x256 Systolic Array aus 8-bit Multiply-Accumulate-Einheiten (MACs). Systolic Arrays verarbeiten Daten in synchronisierten Wellen: Input Activations fließen aus einer Richtung, Weights aus einer anderen, und während diese Datenfronten durch das Gitter laufen, führen sie Matrixmultiplikation mit bemerkenswerter Effizienz aus.
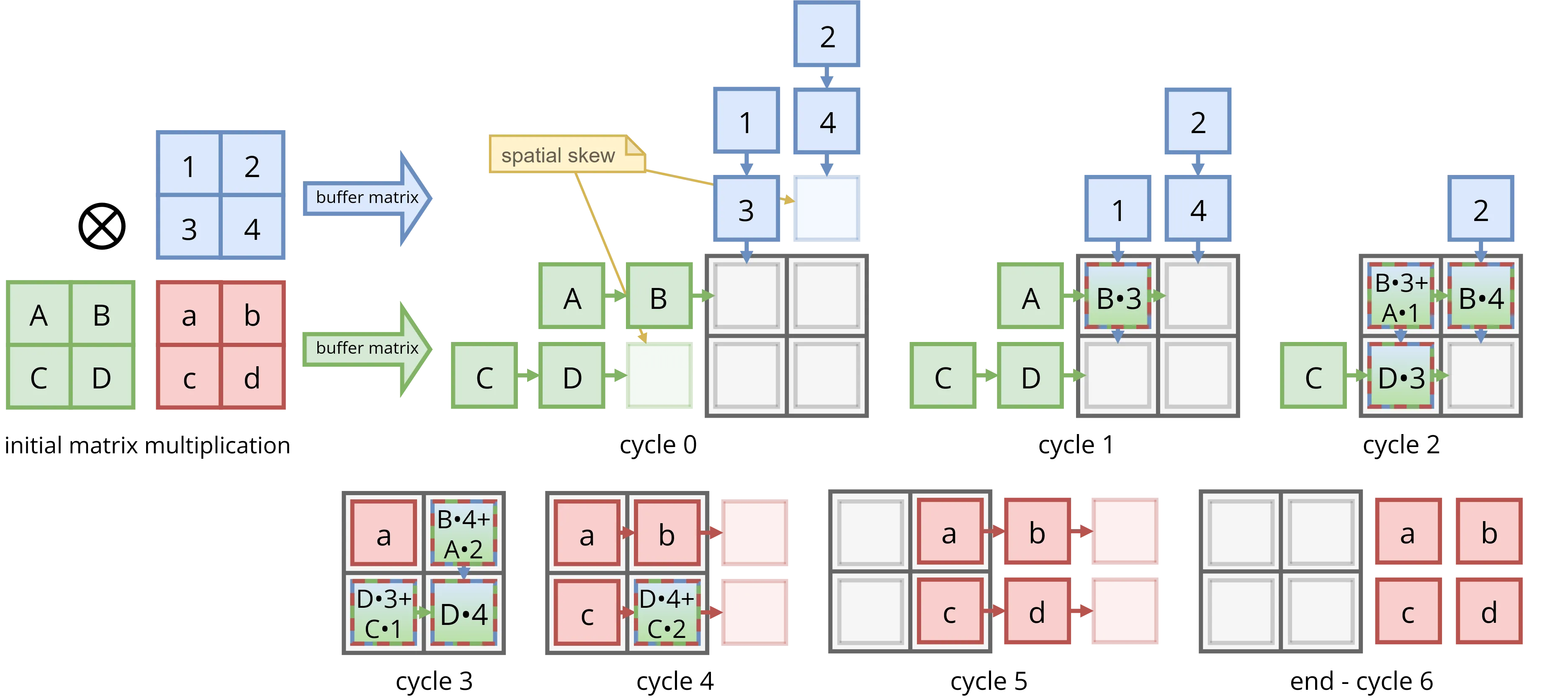
Sobald die Pipeline gefüllt ist, liefert dieses Array 65.536 MAC-Operationen pro Takt. Bei 700 MHz erreicht TPU v1 ungefähr 92 TOPS 8-bit Integer-Performance und übertrifft damit deutlich, was General-Purpose-Hardware damals leisten konnte.
Speicher ohne Caches: Der Unified-Buffer-Ansatz
Vielleicht war die radikalste Entscheidung bei TPU v1, hardwareverwaltete Caches komplett zu streichen. Stattdessen besitzt sie einen 24 MiB großen, softwareverwalteten Scratchpad-Speicher namens Unified Buffer, der 29 % der Die-Fläche belegt. Diese Wahl beseitigte Cache Misses, unvorhersagbare Latenzen und komplexe Kohärenzprotokolle und schuf das deterministische Ausführungsmodell, das für Antwortzeiten im 99. Perzentil entscheidend war.
Der Datenfluss ist elegant einfach: Neural-Network-Weights werden aus 8 GiB DDR3-Speicher auf der Karte in einen Weight-FIFO-Buffer gestreamt, während Input Activations per DMA aus dem Host-Speicher im Unified Buffer bereitgestellt werden. Das Systolic Array konsumiert Daten aus beiden Quellen mit konstanter Rate, Ergebnisse laufen durch Aktivierungsfunktionen und optionale Normalisierung und kehren danach in den Unified Buffer zurück.
Strategische Designentscheidungen
Mehrere zentrale Entscheidungen prägten die Wirksamkeit von TPU v1:
8-bit Integer Arithmetic: Durch den ausschließlichen Betrieb mit quantisierten 8-bit Integers und 32-bit Accumulators erreichte TPU v1 4x Speichereinsparung sowie deutlich kleinere und energieeffizientere MAC-Einheiten als Floating-Point-Alternativen. Google zeigte, dass viele Neural Networks mit vernachlässigbarem Genauigkeitsverlust von 32-bit Floats auf 8-bit Integers quantisiert werden konnten.
Deterministic Execution: Jeder Aspekt von TPU v1 priorisierte vorhersagbare Latenz vor Peak Performance. Diese Philosophie war entscheidend für nutzerseitige Services, bei denen konstante Antwortzeiten wichtiger sind als maximaler Durchsatz.
Process Technology: Auf ausgereifter 28-nm-Technologie bei 700 MHz gebaut, erzielte TPU v1 ihre Gewinne durch architektonische Innovation statt aggressivem Process Scaling. Das zeigte, dass gutes Design rohe Transistorfortschritte übertreffen kann.
Performance-Ergebnisse: Die Vision bestätigt sich
Die reale Performance von TPU v1 bestätigte Googles architektonische Wette. Bei Produktions-Inferenz-Workloads lieferte ein einzelner TPU-Chip 29,2x höheren Durchsatz als eine zeitgenössische Haswell-CPU und 15,3x höheren Durchsatz als eine NVIDIA K80-GPU. Die Effizienzgewinne waren noch deutlicher: 83x bessere Performance pro Watt als die CPU und 29x besser als die GPU.
Noch wichtiger: TPU v1 war unter Latenzdruck stark. In einem Produktionsservice mit 7-ms-Deadline erreichte die Haswell-CPU nur 42 % des Peak-Durchsatzes und die K80-GPU 37 %, weil beide kleine Batches verwenden mussten. TPU v1 hielt unter denselben Bedingungen 80 % Auslastung und zeigte damit ihren architektonischen Vorteil für latenzsensitive Anwendungen.
Performance/Watt Comparison
Relative to CPU or GPU for various TPU generations
Grenzen und Lernchancen
Trotz ihres Erfolgs zeigte TPU v1 wichtige Grenzen. Der Hauptengpass war Speicherbandbreite: DDR3 mit ungefähr 34 GB/s reichte für viele Modelle nicht aus. Googles Analyse zeigte, dass eine hypothetische „TPU v1 Prime“ mit GDDR5-Speicher den Durchsatz verdreifacht und die Effizienz verdoppelt hätte. Speicher war also der entscheidende limitierende Faktor.
Der eilige Entwicklungszeitplan ließ außerdem kein ausgefeiltes Power Management zu. Bei 10 % Auslastung verbrauchte TPU v1 immer noch 88 % der Peak-Leistung, eine schwache Energieproportionalität, die spätere Generationen verbessern sollten.
Am wichtigsten: TPU v1s reine Integer-Arithmetik schloss sie von Training-Workloads aus, die Floating-Point-Berechnungen mit höherer Präzision benötigen. Diese Grenze trieb die grundlegenden Änderungen in TPU v2 an.
TPU v2: Der Weg zur Trainings-Revolution
Bis 2017 war Neural-Network-Training mindestens so rechenintensiv wie Inferenz geworden. State-of-the-Art-Modelle zu trainieren dauerte selbst auf GPU-Clustern Tage oder Wochen. TPU v2 war Googles Antwort: ein Redesign von Grund auf, das Training und Inferenz in bisher unerreichter Skalierung beschleunigen konnte.
bfloat16: Der perfekte technische Kompromiss
Der Wechsel zu Training erforderte Floating-Point-Arithmetik, aber Googles Ingenieure erkannten die Grenzen etablierter Formate. IEEE 754 FP32 bietet sehr gute Präzision, ist aber rechenintensiv. FP16 hat nur einen 5-bit Exponent und braucht deshalb oft algorithmische Umwege wie Loss Scaling, um numerische Instabilität zu vermeiden.
Googles Lösung war bfloat16 (bf16), ein eigenes Format, das FP32s 8-bit Exponent für den vollen Dynamikbereich behält, aber die Mantissa auf 7 Bits reduziert. Diese Designentscheidung war stark: bfloat16 erhält den großen Zahlenbereich, den Training Gradients brauchen, und erreicht gleichzeitig die Rechendichte von 16-bit-Arithmetik.

Architektonische Evolution: Von Single-Core zu Dual-Core
TPU v2 strukturierte die Processing-Architektur grundlegend neu. Statt eines riesigen Systolic Arrays besitzt sie zwei „TensorCores“, jeweils mit einer 128x128 MXU und 16 MiB dediziertem Vector Memory. Dieses Dual-Core-Design liefert ähnliche Gesamt-Rechenleistung, nutzt Speicherbandbreite besser aus und ermöglicht flexibleres Workload Mapping.
Das Speichersystem erhielt das dramatischste Upgrade. TPU v2 ersetzte DDR3 durch 16 GiB High Bandwidth Memory (HBM2) mit 700 GB/s, mehr als 20x die Bandbreite von TPU v1. Damit verschwand die Memory Wall der ersten Generation, und die Recheneinheiten konnten über eine viel breitere Modellpalette effizient laufen.
Skalierung auf Supercomputer-Niveau
Große Modelle zu trainieren erfordert verteilte Berechnung über viele Beschleuniger. TPU v2 wurde genau dafür entworfen und besitzt vier eigene Inter-Core-Interconnect-Links (ICI), jeweils mit 496 Gbit/s Bandbreite. Dadurch können Chips in einer 2D-Torus-Topologie verbunden werden, was effiziente All-to-All-Kommunikation ermöglicht.
Ein vollständiger TPU-v2-„Pod“ besteht aus 256 Chips in einem 16x16-Torus und liefert 11,8 PetaFLOPS Gesamtleistung. In dieser Größenordnung wird der Interconnect genauso wichtig wie die Performance einzelner Chips. Googles eigene Topologie sorgt dafür, dass typische Kommunikationsmuster im verteilten Training mit minimalen Engpässen laufen.
Hardware-Software-Co-Design: Der XLA-Vorteil
Die Hardware-Fähigkeiten von TPU v2 werden durch ausgefeilte Software verstärkt. Der XLA-Compiler (Accelerated Linear Algebra) optimiert ganze Programme, analysiert vollständige Neural-Network-Trainingsgraphen und erzeugt hochoptimierten Code für die spezielle TPU-Architektur.
XLAs Wirkung geht weit über das erste Deployment hinaus. Allein durch Compiler-Optimierungen verbesserte sich TPU-Performance in MLPerf-Trainingsbenchmarks über sechs Monate um einen Median-Faktor von 2,1x. Das zeigt, wie Co-Design Software Hardwarepotenzial auch lange nach der Fertigung des Silicons freisetzen kann.
Weniger öffentlich bekannt war damals, dass TPU v2 bereits „SparseCores“ für sparse Operationen in Recommendation Models integrierte, ein Feature, das Google erst im TPU-v4-Paper öffentlich machte.
TPU v3: Noch mehr Skalierung und Performance
TPU v3 erschien 2018 und war eher eine strategische Weiterentwicklung als ein revolutionäres Redesign. Googles Ingenieure nahmen die bewährte v2-Architektur und verbesserten systematisch jede Komponente, um den wachsenden Rechenbedarf komplexerer Neural Networks zu bedienen.
Architektonische Verfeinerungen
Die wichtigste Änderung in TPU v3 war die Verdopplung der Matrix Units pro TensorCore von eins auf zwei, sodass jeder Chip insgesamt vier 128x128 MXUs besitzt. Zusammen mit einer höheren Taktrate von 940 MHz ergab das 123 TFLOPS bfloat16-Performance pro Chip, eine theoretische Verbesserung um 2,7x gegenüber v2.
Die Speicherkapazitäten skalierten proportional: HBM2-Kapazität verdoppelte sich auf 32 GiB pro Chip, die Bandbreite stieg auf 900 GB/s. Auch der Inter-Core Interconnect erhielt 32 % mehr Bandbreite und kam auf 656 Gbit/s pro Link, damit Kommunikation mit der höheren Rechenleistung mithalten konnte.
Trotz verdoppelter MXU-Anzahl wuchs die Die-Fläche von TPU v3 nur um 6 % gegenüber v2. Diese Effizienz entstand durch Design-Erfahrung: Das Team hatte gelernt, Floorplans zu optimieren und verschwendete Silicon-Fläche zu minimieren. Das zeigt den Wert iterativer Architekturverbesserung.
Performance auf Supercomputer-Niveau
TPU v3 erhöhte die maximale Pod-Größe auf 1024 Chips, viermal so groß wie v2-Pods. Ein vollständig konfigurierter TPU-v3-Pod liefert über 126 PetaFLOPS und hält dabei 96-99 % lineare Skalierungseffizienz bei Produktions-Workloads. Diese fast perfekte Skalierung bei über tausend Chips ist eine bemerkenswerte Leistung im Distributed-System-Design.
Die höhere Performance-Dichte brachte thermische Herausforderungen mit sich. TPU v3s 450W TDP erforderte Flüssigkeitskühlung, da Luftkühlung die Wärmedichte in Datacenter-Racks nicht bewältigen konnte. Dieser Wechsel zeigt die dauerhafte Spannung zwischen Performance und praktischen Deployment-Grenzen.
„What You Train Is What You Serve“
TPU v3 stärkte Googles „WYTIWYS“-Philosophie (What You Train Is What You Serve). Anders als Workflows, die separate Quantisierungsschritte für Inferenz-Deployment brauchen, nutzt TPU v3 bfloat16 für Training und Serving. Das vermeidet mögliche Genauigkeitsverluste durch Formatkonvertierung und vereinfacht die Machine-Learning-Pipeline.
Performance-Ergebnisse bestätigten diesen Ansatz. Im LSTM0-Benchmark erreichte TPU v3 45 ms Inferenzlatenz und war damit schneller als die inference-optimierte TPU v1, die für dieselbe Aufgabe 122 ms benötigte. Das zeigte, dass die trainingsorientierte v2/v3-Architektur auch bei Inferenz stark sein konnte und dabei numerisch konsistent mit dem Training blieb.
Moderne TPU-Entwicklung (v4-v7): Grenzen verschieben
Die architektonischen Prinzipien aus TPU v1-v3 entwickeln sich in späteren Generationen weiter. Jede adressiert neue Herausforderungen in KI-Berechnung auf immer größerer Skala. Während detaillierte akademische Analysen vor allem für die ersten drei Generationen existieren, geben offizielle technische Ankündigungen Einblick in Googles weitere Innovationen.
TPU v4: Optische Interconnects und spezialisierte Beschleunigung
TPU v4 erschien 2020 und erreichte 2,1x mehr Performance sowie 2,7x bessere Performance pro Watt gegenüber v3. Jeder Chip liefert 275 TFLOPS bfloat16-Performance mit 32 GiB HBM und 1,2 TB/s Bandbreite. Die wichtigsten Innovationen von v4 gehen jedoch über reine Compute-Metriken hinaus.
Die Einführung von Optical Circuit Switches (OCS) ermöglicht dynamische Rekonfiguration des 3D-Torus-Interconnects, verbessert Fehlertoleranz und erlaubt spezialisierte Netzwerktopologien für unterschiedliche Kommunikationsmuster. Diese Flexibilität wird entscheidend, wenn Pod-Größen auf 4096 Chips und darüber hinaus wachsen.
Das v4-Paper machte außerdem TPUs dedizierte „SparseCores“ öffentlich: spezialisierte Prozessoren für sparse Operationen, wie sie in Recommendation Systems und embedding-lastigen Modellen häufig vorkommen. Seit v2 vorhanden, beschleunigen sie Deep Learning Recommendation Models um 5-7x und verbrauchen dabei nur ungefähr 5 % der Die-Fläche und Leistung. Das unterstreicht den Wert heterogener Beschleunigung innerhalb domänenspezifischer Architekturen.
TPU-v5-Familie: Aufteilung nach Effizienz und Performance
Disclaimer: Für TPU v5 und spätere Generationen (einschließlich v5e/v5p, v6e und v7) basieren die hier genannten Spezifikationen und Performance-Werte auf Googles öffentlichen Aussagen und Ankündigungen, nicht auf peer-reviewten wissenschaftlichen Papers.
Mit TPU v5 formalisierte Google einen zweigleisigen Ansatz für unterschiedliche Marktsegmente und Use Cases:
TPU v5e (Efficient): Für kostenbewusste Deployments entworfen, mit 197 TFLOPS, 16 GB HBM und 0,82 TB/s Bandbreite. Diese Variante richtet sich an Organisationen, die solide ML-Performance ohne Premium-Preis brauchen.
TPU v5p (Performance): Für maximalen Durchsatz im großen Maßstab gebaut, mit 459 TFLOPS, 95 GB HBM und 2,8 TB/s Bandbreite. Pods skalieren auf 8.960 Chips mit 4,8 Tb/s Bisection Bandwidth und zielen auf die größten Trainings-Workloads sowie anspruchsvollste Inferenzanwendungen.
TPU v6e „Trillium“: Effizienzsprung
TPU v6e ist ein deutlicher Fortschritt in der effizienzorientierten Linie: 918 TFLOPS pro Chip, fast doppelt so viel wie v5e. Die Speicherkapazität stieg auf 32 GB mit 1,64 TB/s Bandbreite, während die Interconnect-Bandbreite sich mehr als verdoppelte. Am wichtigsten: v6e liefert 67 % bessere Energieeffizienz gegenüber v5e und ist dadurch besonders attraktiv für große Deployments, bei denen Stromverbrauch die Betriebskosten direkt beeinflusst.
TPU v7 „Ironwood“: Die speicherzentrierte Zukunft
TPU v7 wurde für 2025 angekündigt und adressiert eine der drängendsten Herausforderungen moderner KI: Speicherkapazität. Mit 192 GB HBM pro Chip bei 7,4 TB/s Bandbreite kann v7 deutlich größere Modelle auf dem Chip halten, ohne ständig Daten aus externem Storage streamen zu müssen.
Die Compute-Leistung skaliert passend dazu: Über 4,6 PFLOPS pro Chip bedeuten 5x mehr als v6e. Die eigentliche Innovation liegt aber darin, diese Performance mit dem Ziel von 2x besserer Performance pro Watt zu erreichen. Damit setzt sich der Trend fort, jede Generation energieeffizienter zu machen, obwohl die absolute Performance massiv steigt.
TPU-Entwicklung: Spezifikationen auf einen Blick
| Generation | Peak Compute | Precision | Memory / Bandwidth | Interconnect | Max Pod Size | Key Features |
|---|---|---|---|---|---|---|
| v1 | 92 TOPS (8-bit) | INT8 | 8 GiB DDR3 / 34 GB/s | N/A | Einzelchip | Nur Inferenz, PCIe-Karte, 75W TDP |
| v2 | 46 TFLOPS (bfloat16) | bfloat16 | 16 GiB HBM2 / 700 GB/s | 4× ICI @ 496 Gbit/s | 256 Chips (11,8 PFLOPS) | Dual TensorCores, trainingsfähig |
| v3 | 123 TFLOPS (bfloat16) | bfloat16 | 32 GiB HBM2 / 900 GB/s | 4× ICI @ 656 Gbit/s | 1024 Chips (126 PFLOPS) | Flüssigkeitskühlung, 4× MXUs pro Chip |
| v4 | 275 TFLOPS (bfloat16) | bfloat16 | 32 GiB HBM / 1.2 TB/s | OCS + 3D torus | 4096 Chips | Optischer Interconnect, SparseCores seit v2 |
| v4i | ~275 TFLOPS (bfloat16) | bfloat16 | 32 GiB HBM / 1.2 TB/s | N/A | Einzelchip | Inferenz-optimiert, luftgekühlt |
| v5e | 197 TFLOPS (bfloat16) | bfloat16 | 16 GB HBM / 0.82 TB/s | Standard | Variabel | Kosteneffizientes Training/Inferenz |
| v5p | 459 TFLOPS (bfloat16) | bfloat16 | 95 GB HBM / 2.8 TB/s | 4.8 Tb/s bisection | 8960 Chips | High-Performance-Training |
| v6e | 918 TFLOPS (bfloat16) | bfloat16 | 32 GB HBM / 1.64 TB/s | >2× v5e | Variabel | 67 % bessere Effizienz gegenüber v5e |
| v7 | >4.6 PFLOPS (bfloat16) | bfloat16 | 192 GB HBM / 7.4 TB/s | TBD | TBD | 2× perf/W gegenüber v6e (2025 angekündigt) |
Architekturparadigmen: GPU vs FPGA vs TPU
Der Erfolg von TPUs hat die breitere Einführung domänenspezifischer Beschleuniger in der Industrie katalysiert, aber unterschiedliche Architekturansätze bedienen unterschiedliche Use Cases. Wann GPUs, FPGAs oder TPUs sinnvoll sind, hängt von den grundlegenden Trade-offs zwischen Programmierbarkeit, Latenz, Durchsatz und Effizienz ab.
Das Latenz-Durchsatz-Spektrum
Jede Architektur optimiert für andere Punkte im Latenz-Durchsatz-Spektrum:
FPGAs sind stark bei Ultra-Low-Latency: Microsofts Brainwave-Projekt zeigte, dass FPGAs bei komplexen Modellen Sub-4-ms-Inferenzlatenz erreichen können, indem sie feingranulare Parallelität aus einzelnen Requests extrahieren. Der Hierarchical-Decode-and-Dispatch-Mechanismus kann eine Instruktion in über 7 Millionen primitive Operationen expandieren, ohne Batching zu benötigen. Dadurch eignen sich FPGAs für Real-Time-Anwendungen, bei denen einzelne Request-Latenz wichtiger ist als Gesamtdurchsatz.
TPUs und GPUs optimieren für gebatchten Durchsatz: Beide Architekturen erreichen Peak-Effizienz mit größeren Tensor-Operationen, die ihre massiven parallelen Compute Arrays auslasten. TPUs gewinnen zusätzlich durch deterministische Ausführung: Da Cache Misses und andere Quellen von Latenzvarianz eliminiert werden, können sie selbst unter strikten 99.-Perzentil-Latenzgrenzen näher am Peak-Durchsatz arbeiten.
Flexibilität vs Spezialisierung
Das Architekturspektrum spiegelt unterschiedliche Philosophien zur Anpassbarkeit wider:
GPUs bieten maximale Programmierbarkeit: NVIDIAs CUDA-Ökosystem ermöglicht schnelles Prototyping und unterstützt viele Modellarchitekturen. Diese Flexibilität macht GPUs in Forschungsumgebungen unverzichtbar, wo neue Techniken schnell entstehen. General-Purpose-Design bringt jedoch Overhead mit sich, den spezialisierte Architekturen vermeiden.
FPGAs bieten rekonfigurierbare Spezialisierung: Die Fähigkeit, eigene Datapaths und Zahlenformate zu synthetisieren (wie Microsofts Block Floating-Point), bildet einen Mittelweg zwischen Flexibilität und Effizienz. FPGAs können sich durch Hardware-Rekonfiguration an neue Modellarchitekturen anpassen, nicht nur durch Softwareänderungen.
TPUs erreichen Effizienz durch Co-Design: Obwohl die Hardware nach der Fertigung fix ist, ermöglicht die enge Integration mit dem XLA-Compiler kontinuierliche Optimierung. Google zeigte mediane 2,1x Performance-Verbesserungen in MLPerf-Benchmarks allein durch Softwareoptimierung, was zeigt, dass ASIC-Plattformen durch Compiler-Fortschritt weiterentwickelt werden können.
Architekturvergleich von KI-Beschleunigern
| Attribut | GPU (z. B. NVIDIA Volta) | FPGA (z. B. MS Brainwave) | TPU (Google v1-v3) |
|---|---|---|---|
| Architektur | Programmierbarer Parallelprozessor | Rekonfigurierbare Logik | Domänenspezifischer ASIC |
| Primäre Stärke | Flexibilität und Forschungsgeschwindigkeit | Ultra-Low-Latency (Batch-of-1) | Durchsatz und Effizienz im großen Maßstab |
| Compute Primitive | SIMT-Cores (threadbasiert) | Matrix-Vektor-Operationen | Systolic Matrix-Matrix-Arrays |
| Speichersystem | Hardware-Caches + HBM | Softwareverwaltetes SRAM | Softwareverwaltetes SRAM + HBM |
| Skalierungsmodell | NVLink + InfiniBand | Network-attached Services | Eigene Torus-/OCS-Pods |
| Beste Use Cases | Diverse ML-Workloads, Forschung | Latenzkritische Inferenz | Large-Scale-Training, gebatchte Inferenz |
System-Level-Integrationsstrategien
Über die Performance einzelner Chips hinaus unterscheiden sich diese Architekturen grundlegend in ihrer Systemintegration:
Disaggregated vs. Integrated Scaling: Microsofts Brainwave behandelt FPGAs als network-attached „Hardware Microservices“ und ermöglicht flexible Ressourcenzuteilung. TPU Pods dagegen sind speziell gebaute Supercomputer mit eigenen Torus-Interconnects, optimiert für bestimmte Kommunikationsmuster im verteilten Training.
Communication Architecture: GPUs nutzen etablierte Standards wie NVLink und InfiniBand für Kommunikation zwischen Geräten. TPUs verwenden eigene Inter-Core Interconnects (ICI) und Optical Circuit Switches (OCS), die speziell für ML-Kommunikationsmuster entwickelt wurden. Diese Spezialisierung ermöglicht nahezu perfekte lineare Skalierung auf 1000+ Chips, reduziert aber die Flexibilität für andere Workload-Typen.
Auswirkungen und Zukunft
Transformation der Industrie
Der Erfolg des TPU-Projekts validierte domänenspezifische Architektur als echte Alternative zu General-Purpose-Scaling. Das löste branchenweite Innovation aus: AWS entwickelte Inferentia und Trainium, Microsoft Brainwave, Intel Gaudi, und NVIDIA ergänzte GPUs um spezialisierte Tensor Cores. Die Wettbewerbslandschaft bietet heute diverse Ansätze für KI-Beschleunigung statt allein auf General-Purpose-Prozessoren zu setzen.
Architektur-Lektionen und Prinzipien
Aus der Entwicklung von TPU v1-v3 ergeben sich mehrere zentrale Prinzipien:
Hardware-Software-Co-Design verstärkt Vorteile: Die enge Integration zwischen TPU-Hardware, TensorFlow-Framework und XLA-Compiler ermöglichte Optimierungen, die mit generischen Interfaces unmöglich wären. Dieser Co-Design-Ansatz ist inzwischen Standard in der Industrie.
Deterministic Execution ermöglicht vorhersagbare Performance: Durch das Entfernen von Latenzvarianz-Quellen wie Cache Misses und komplexem Scheduling können TPUs unter strikten Tail-Latency-Anforderungen hohe Auslastung halten. Diese Vorhersagbarkeit ist für nutzerseitige KI-Services entscheidend.
Speicherarchitektur folgt Compute-Skalierung: Der Weg von DDR3 (v1) über HBM2 (v2/v3) zu massiver HBM-Kapazität (v7) spiegelt die wachsende Bedeutung von Speicherbandbreite und Kapazität wider, während Modellgrößen exponentiell steigen.
Zukünftige Herausforderungen und Chancen
Die TPU-Roadmap zeigt mehrere zentrale Trends, die die Zukunft von KI-Hardware prägen:
Speicherzentriertes Design: TPU v7s 192 GB On-Chip-Speicher adressieren die Realität, dass Modellparameter schneller wachsen als Speicherkapazität. Künftige Architekturen werden Speichersysteme vermutlich genauso stark priorisieren wie Compute Units.
Energieeffizienz als First-Class Concern: Jede TPU-Generation verbessert Performance pro Watt, obwohl absolute Performance stark steigt. Da Trainingskosten Millionen von Dollar erreichen und erhebliche Umweltauswirkungen haben, werden Effizienzgewinne genauso wichtig wie rohe Performance.
Heterogene Beschleunigung: Zukünftige Designs werden wahrscheinlich verschiedene Beschleuniger integrieren, die für unterschiedliche Operationstypen in KI-Workloads optimiert sind.
Die TPU-Geschichte zeigt: Wenn konventionelle Ansätze an ihre Grenzen stoßen, kann fokussierte architektonische Innovation Durchbrüche erzielen. Die zentrale Erkenntnis ist nicht nur, schnellere Chips zu bauen, sondern Hardware und Software gemeinsam zu entwerfen und kompromisslos für die wichtigsten Workloads zu optimieren.
Fazit: Lektionen für die Zukunft von KI-Hardware
Googles TPU-Reise von v1s inferenzfokussiertem Design bis zu v7s Massive-Memory-Architektur zeigt, wie domänenspezifische Innovation scheinbar unüberwindbare Skalierungsprobleme lösen kann. Angesichts exponentiell wachsender KI-Rechenanforderungen entschied sich Google für Spezialisierung statt Generalisierung und erreichte Performance-Gewinne, die über traditionelle Skalierungsansätze unmöglich gewesen wären.
Die in TPU v1-v3 etablierten Architekturprinzipien treiben weiterhin Innovation in der Industrie. Für Matrixoperationen optimierte Systolic Arrays, softwareverwaltete Speicherhierarchien ohne unvorhersagbare Latenzen, eigene Interconnects für ML-Kommunikationsmuster und enges Hardware-Software-Co-Design sind Standardpraktiken in der Entwicklung von KI-Beschleunigern geworden.
Vielleicht am wichtigsten: Das TPU-Projekt zeigte, dass Durchbruch-Performance mehr braucht als schnellere Transistoren oder höhere Taktraten. Die größten Gewinne entstehen, wenn du deinen Workload tief verstehst, Hardware gezielt für diese Muster entwirfst und Software mitentwickelst, um das Potenzial der Architektur auszuschöpfen. Während KI die Grenzen des Rechnens weiter verschiebt, wird diese Philosophie fokussierter, gemeinsam entwickelter Spezialisierung wahrscheinlich die nächste Generation von Durchbruchsarchitekturen prägen.
Weiterlesen: Akademischer Deep Dive
Dieser Blogpost bietet einen zugänglichen Überblick über Googles TPU-Architekturevolution. Wenn du tiefer in die technische Analyse einsteigen möchtest, inklusive detaillierter Performance-Modellierung, vergleichender Benchmarks und architektonischer Trade-offs, bietet meine vollständige Seminararbeit eine umfassende akademische Behandlung mit vollständigen Zitaten der Primärforschung.
Hinweis: Diese Arbeit wurde im Rahmen einer universitären Lehrveranstaltung eingereicht und nicht unabhängig peer-reviewed.
Vollständige Seminararbeit herunterladen (PDF)