
Ich wurde vor Kurzem in das Generation Developer (GenDev)-Stipendium von CHECK24 aufgenommen, eine riesige Ehre und eine starke Chance. Bevor gefeiert werden konnte, gab es aber noch eine kleine Hürde: eine umfangreiche Coding Challenge. Die Aufgabe? Ein Full-Stack-Portal zum Echtzeitvergleich von Internetanbietern von Grund auf bauen.
Dieser Post erzählt die Geschichte dieses Projekts, das ich BetterSurf genannt habe. Es ist ein Deep Dive in Engineering-Entscheidungen, architektonische Rabbit Holes und Resilience Patterns, mit denen ich ein System gebaut habe, das nicht nur funktioniert, sondern im Chaos mehrerer unvorhersehbarer Third-Party-Services sogar stabil bleibt (ServusSpeed 😡). Schauen wir unter die Haube.
Die API-Clownshow
Die Aufgabe war, ein Full-Stack-Vergleichsportal zu bauen, das Angebote aus fünf verschiedenen Provider-APIs sammelt und sie in einer nutzerfreundlichen Echtzeitoberfläche präsentiert.
Um ein realistisches Szenario zu simulieren, gab CHECK24 mir nicht einfach fünf saubere REST APIs. Natürlich nicht, das wäre zu einfach gewesen. Stattdessen gab es eine wunderbar chaotische Mischung simulierter Services, jeder mit eigenen Eigenheiten und Persönlichkeitsstörungen. Die eigentliche Herausforderung war, diesen digitalen Zirkus zu orchestrieren:
WebWunder (Das Relikt)
Ein Legacy-SOAP-Endpunkt. Das bedeutete: die zeep-Library entstauben und mit WSDL-Dateien und XML-Requests kämpfen. Selbst das reichte aber nicht, weil die API Probleme mit dem Standardformat hatte. Ich musste also das erwartete XML rekonstruieren und um rohes XML herumarbeiten. Ein echter Gruß aus der Vergangenheit.
ByteMe (Der CSV-Spucker)
Diese REST API entschied, dass JSON zu Mainstream ist, und lieferte eine rohe CSV-Datei zurück. Ich musste mit pandas eine kleine Datenpipeline bauen, um den Output zu holen, zu parsen und zu bereinigen. Insgesamt nicht so schlimm. Allerdings war die CSV oft malformed oder kaputt. Das ließ sich mit einem sauberen Factory Pattern lösen. Dazu gleich mehr.
PingPerfect (Der Gatekeeper)
Eine normale REST/JSON API, aber mit Haken: Jeder einzelne Request musste mit HMAC-SHA256 signiert werden. Auch das war noch machbar.
VerbynDich (Der langsame Tropf)
Eine paginierte REST API, die Geduld verlangte. Um es zu beschleunigen, holte ich Seiten parallel, nutzte aber ein asyncio.Semaphore, um sie nicht mit Requests zu überfahren. Herauszufinden, wie viele Requests sie gleichzeitig aushält, wurde fast zur Wissenschaft: manchmal 10, manchmal nur 4! Noch eine Eigenheit: Sie lieferte nur Fließtext zurück. Ich musste Regex-Patterns nutzen, um relevante Daten zu extrahieren, und weil die Antworten stark variierten, entstand am Ende ein ziemlich großes Regelwerk.
ServusSpeed 😡 (Die Schnecke)
Eine berüchtigt langsame Multi-Step-API: erst ein Call für Produkt-IDs, danach parallele Detailrequests für jede ID. Die initiale ID-Liste konnte bis zu 15 s dauern, jeder Detailcall weitere 15 s, plus Throttling, wenn man mehr als drei gleichzeitig laufen ließ! Interessanterweise wurde ServusSpeed manchmal drastisch schneller (2-3 s), wenn das Backend auf einer AWS EC2-Instanz lief. Aber eben nicht immer. Meine Gegenmaßnahmen erkläre ich später.
Mein Blueprint für Vernunft: eine entkoppelte Architektur
Wie zähmt man so ein Chaos? Meine Antwort war eine klassische entkoppelte Two-Tier-Architektur. Auf der einen Seite ein schnelles Next.js 15 (React 19)-Frontend, gestylt mit Tailwind CSS und shadcn/ui, das alles übernimmt, was der Nutzer sieht. Auf der anderen Seite ein robustes FastAPI (Python)-Backend für die schwere Arbeit. Diese Trennung war nicht verhandelbar. Sie hält API Keys und komplexe Integrationslogik sicher auf dem Server und lässt das Frontend schlank, schnell und sicher bleiben.


Regel Nr. 1: Rechne damit, dass Dinge kaputtgehen
Wenn du fünf externe APIs jonglierst, werden Dinge kaputtgehen. Es ist keine Frage von ob, sondern wann. Eine Kernanforderung war, dass ein ausfallender Provider nicht die ganze App mitreißen darf. Meine erste Priorität war deshalb eine mehrschichtige Resilience-Strategie.
Intelligente Retries mit Tenacity
Jeder externe API-Call wurde in meine Geheimwaffe gepackt: den @tenacity.retry-Decorator. Das war aber keine blinde „einfach nochmal versuchen“-Schleife, sondern eine kalkulierte Strategie:
Das System versucht den Call dadurch bis zu 8 Mal. Es startet mit einer sehr kleinen Verzögerung und geht exponentiell bis auf 1 Sekunde hoch. So bekommt ein wackeliger Service Zeit, sich zu erholen. Entscheidend: Es wird nur bei bestimmten, temporären Fehlern erneut versucht, etwa Netzwerkproblemen (httpx.HTTPError) oder einem eigenen ProviderError. Bei permanenten Fehlern wie 401 Unauthorized schlagen wir schnell fehl, statt Zeit zu verschwenden.
Das Circuit Breaker Pattern
Retries sind gut, aber was ist, wenn ein Service komplett down ist? Ihn permanent zu bombardieren macht es nur schlimmer. Um das zu verhindern, habe ich für jeden Provider einen Circuit Breaker implementiert. Stell es dir wie einen Stromkreis im Haus vor:
- Closed (Alles gut): Requests laufen normal.
- Open (Etwas stimmt nicht): Nach 5 Fehlern in Folge „springt“ der Circuit auf und öffnet sich. Für die nächsten 5 Sekunden versuchen wir nicht einmal, die API aufzurufen. Wir schlagen sofort fehl, sparen Ressourcen und geben dem ausgefallenen Service eine Pause. Der 5-Sekunden-Timeout könnte erhöht werden, aber für die Demo wollte ich maximale Responsiveness.
- Half-Open (Testlauf): Nach dem Cooldown lassen wir einen einzelnen Testrequest durch. Klappt er, schließt der Circuit. Scheitert er, öffnen wir ihn wieder.
Das Abstract Provider Pattern
Um diese Regeln sauber anzuwenden, erstellte ich eine abstrakte ProviderBase-Klasse. Die gesamte Resilience-Logik (Tenacity, Circuit Breaker) lebte dort. Jede konkrete Providerklasse, zum Beispiel WebWunderProvider, erbte dann einfach von dieser Basis. Das war ein Lebensretter: Es hielt meinen Code DRY und stellte sicher, dass jede einzelne Integration gleich robust war, ohne mich zu wiederholen.


Datenchaos in Klarheit verwandeln
Wenn die APIs ein chaotischer Basar waren, dann waren die zurückgegebenen Daten ein Durcheinander unpassender Waren. Ich bekam inkonsistente Feldnamen, seltsame Formate und unzuverlässige Werte. Hier wurde Pydantic mein bester Freund: wie ein strenger, aber fairer Türsteher am Eingang meiner Anwendung. Ich definierte ein einzelnes, einheitliches Offer-Model als Source of Truth, das alle eingehenden Daten zu Folgendem zwang:
- In Reih und Glied (Strict Types): Kein „ist das ein String oder eine Zahl?“ mehr. Jedes Feld wurde in den richtigen Typ gecastet (`int`, `float` usw.).
- Schluss mit Floating-Point-Unsinn: Alles Geld wurde in Integer-Cents umgewandelt. Dadurch vermeidet man die berüchtigten Floating-Point-Rundungsfehler, die Finanzberechnungen nerven.
- Eine gemeinsame Sprache sprechen: Vertragslaufzeiten wie „12 Monate“, „1 Jahr“ und `12` wurden alle in eine saubere Integer `12` normalisiert.
- Schlauer werden (Computed Fields): Das Model reicherte Daten automatisch an. Wenn ein rohes Angebot etwa ein `tv_package_name` hatte, wurde automatisch ein Boolean `tv_included` auf `true` gesetzt.
- Und vieles mehr: Ich habe wirklich Arbeit investiert, damit Parsing und Validierung robust sind.
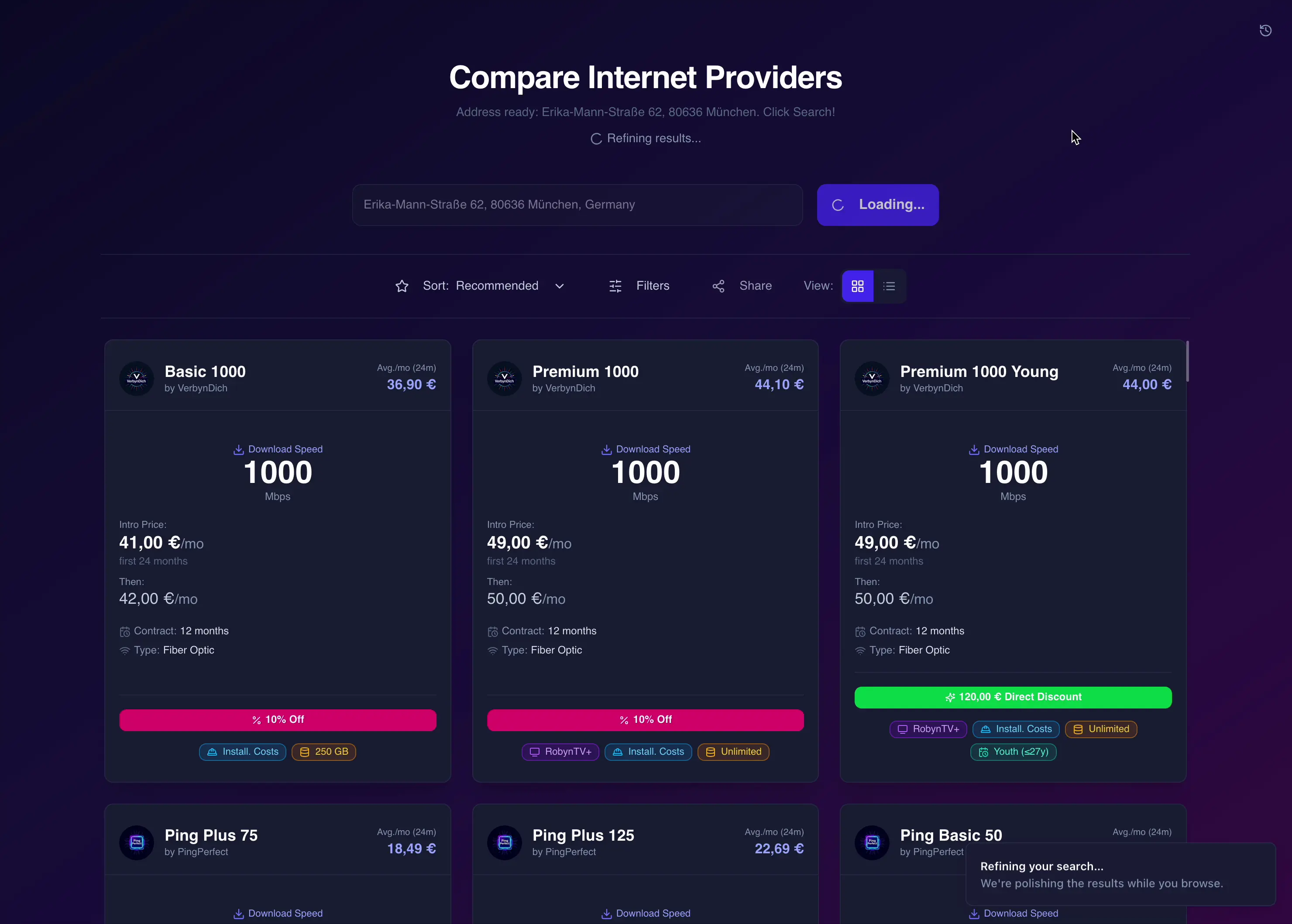
Die Illusion von Geschwindigkeit: Real-Time mit WebSockets
Niemand starrt gern auf einen Loading Spinner. Da ich die externen APIs nicht magisch beschleunigen konnte (besonders dich, ServusSpeed 😡), optimierte ich für wahrgenommene Performance. Die Lösung war ein zweiphasiges Ladesystem über eine einzelne WebSocket-Verbindung. Der Trick:
- Wenn ein Nutzer auf „Suchen“ klickt, startet das Backend alle API-Calls parallel.
- Dann wartet es auf die schnelleren Provider (oder einen 10-Sekunden-Timeout). Sobald diese erste Charge bereit ist, streamt es ein
INITIAL_OFFERS-Payload ans Frontend. - Die UI rendert diese Ergebnisse sofort. Der Nutzer bekommt in Sekunden Daten. Währenddessen wartet das Backend geduldig auf die langsamen Kandidaten. Wenn sie fertig sind, sendet es ein
FINAL_OFFERS-Payload, und die UI bietet nahtlos an, die vollständige Liste zu übernehmen.
Dadurch fühlt sich die App extrem schnell an und liefert sofort Wert, auch wenn die vollständige Datenarbeit im Hintergrund etwas länger dauert.
Noch einen draufsetzen: die smarten Features
Eine wirklich „Recommended“-Sortierung
Ich wollte nicht, dass die Standard-Sortierung „Recommended“ zufällig ist. Also schrieb ich einen eigenen clientseitigen Algorithmus, der jedes Angebot danach bewertet, was für echte Nutzer relevant sein könnte. Er berechnet einen gewichteten Score anhand von:
- Dem effektiven Monatspreis über 24 Monate.
- Download- und Upload-Geschwindigkeit.
- Preis-Leistung (Geschwindigkeit pro Euro).
- Anschlusstyp (Fiber bekommt einen netten Boost!).
- Extras wie TV-Pakete oder Jugendrabatte.
Smartere Eingabe, weniger Frust
Um die Suche einfacher zu machen, integrierte ich die Google Places API für Address Autocompletion. Das reduziert Tippfehler drastisch. Es ist die einzige Eingabemethode und erlaubt Nutzern, die Adresse in jedem Format einzugeben, solange Google Places einen passenden Treffer findet. Auf der Sicherheitsseite ist der API Key auf die Production-Domain beschränkt. Außerdem fügte ich „Recent Searches“ hinzu, das die letzten fünf Suchen des Nutzers in `localStorage` speichert, damit man einen Vergleich mit einem Klick wieder öffnen kann. Intern nutzt das denselben Mechanismus wie die teilbaren Links, also war die Implementierung relativ geradlinig.
Spotlight: Ein teilbarer Link, der wirklich funktioniert
Ich wollte ein Sharing-Feature bauen, das einfach zu benutzen ist und zuverlässig funktioniert. So habe ich es umgesetzt:
- Wenn ein Nutzer auf „Teilen“ klickt, sendet das Frontend die Suchfilter, den Offer-Slug (vom Backend zur Identifikation der Suchergebnisse gesendet) und optional einen Offer-Key (falls nur ein einzelnes Angebot geteilt wird) an einen speziellen Backend-Endpunkt.
- Das Backend nimmt Filter und Slug, komprimiert sie mit zlib und kodiert sie mit base64url in einen URL-sicheren Slug.
- Dann speichert es die tatsächliche Angebotsliste dieser Suche in Redis, nutzt den Slug als Key und lässt ihn nach 24 Stunden ablaufen.
- Wenn jemand den geteilten Link öffnet, nutzt das Frontend den Slug, um exakt diese Ergebnisse aus der API zu holen. Die API holt sie wiederum aus Redis und rekonstruiert die ursprüngliche Suche perfekt.
Bereit für die Bühne: Testing & Deployment
Eine Testing-Kultur
Ein komplexes System wie dieses ist ohne Tests fragil. Ich nutzte Pytest, um eine Suite zu bauen, die 100 % der Dateien ausführt und ~93 % Line Coverage erreicht. Der Schlüssel war aggressives API Mocking. Mit Monkey-Patching ersetzte ich Netzwerkaufrufe durch Fake Responses. So konnte ich alles simulieren: Erfolg, seltsame Fehler, Timeouts, alles. Nur so konnte ich sicher sein, dass meine Resilience-Logik wirklich funktioniert. Ein weiterer großer Teil des Testings fokussierte sich auf die Factory-Logik: Egal was ein Provider zurückgibt, die Factories sollten entweder ein valides Offer-Objekt zurückgeben oder das Angebot verwerfen, aber trotzdem so viele Daten wie möglich auffüllen, selbst wenn der Output kaputt war.
Von meinem Laptop in die Cloud
Das Backend ist vollständig mit Docker und Docker Compose containerisiert und bündelt FastAPI-App, Nginx und Redis. Dieser Stack läuft auf einer AWS EC2-Instanz, auf der Nginx als Reverse Proxy agiert. Davor sitzt AWS CloudFront für globales CDN und SSL. Das Next.js-Frontend ist auf Vercel deployt, wegen des starken CI/CD-Workflows, Edge Networks und der einfachen Bedienung.
Eine große Lektion hier war State. Meine erste Share-Implementierung nutzte einen simplen In-Memory-Cache. Lokal funktionierte das, weil ich in Dev Uvicorn mit einem einzelnen Worker nutzte. In Production mit mehreren Gunicorn-Workern war es eine Katastrophe. Jeder Worker hatte seinen eigenen Cache, also wurde der Share-State nicht geteilt. Dieser „aha!“-Moment brachte mich zu Redis als zentralem Cache, obwohl ich es anfangs vermeiden wollte, weil es nach Overkill klang und Caching von Ergebnissen sowieso nicht erlaubt war. Dadurch wurde die gesamte Anwendung über alle Worker hinweg wirklich robust.
Rückblick: Learnings und Zukunftspläne
Dieses Projekt war ein Biest, im besten Sinne. Es war ein intensiver Crashkurs in echter Softwareentwicklung.
Was ich in der Praxis gelernt habe
- Praktisches API-Wrangling: Ich habe von altem SOAP bis modernem REST alles angefasst und gelernt, wie man jeden einzelnen Ansatz bändigt.
- Echte Resilience Engineering: Ich habe das Circuit Breaker Pattern nicht nur gelesen, sondern gebaut, debuggt und verstanden, warum es so wichtig ist.
- Die Kunst von Real-Time UX: Ich habe gelernt, wie man mit WebSockets eine Experience baut, die schnell und responsiv wirkt, selbst wenn das Backend hart arbeitet. Außerdem, wie wichtig es manchmal ist, Nutzer über das, was intern wirklich passiert, ein bisschen zu täuschen. Der Nutzer muss nicht wissen, dass irgendeine API langsam ist. Er sieht Ergebnisse und ist zufrieden.
- Production-Kopfschmerzen und Gegenmittel: Ich habe aus erster Hand gelernt, warum Dinge, die in Development funktionieren, in Production brechen, und wie Tools wie Redis echte Skalierungsprobleme lösen.
Wenn ich es nochmal machen würde...
Mit etwas Abstand gibt es ein paar Dinge, die ich verfeinern würde:
- Sauberere API-Interfaces: Ich würde die Providerklassen noch stärker auf ihre Single Responsibility zuschneiden, damit sie leichter wartbar sind.
- Formale Dependency Injection: Eine DI-optimierte Backend-Architektur würde Testing und Konfiguration noch schlanker machen.
- Hyper-responsive Fetching: Ich würde das zweiphasige Laden zu einem mehrphasigen System weiterentwickeln, das Ergebnisse streamt, sobald irgendein einzelner Provider fertig ist.
Die Wishlist für BetterSurf 2.0
Wenn ich das wirklich weiterentwickeln würde, gäbe es ein paar Dinge, die meiner Meinung nach sehr nötig wären.
- Smarteres Caching: Auch wenn Caching in der Challenge verboten war, würde ich einen mehrstufigen Cache in Redis für Providerantworten und vollständige Suchergebnisse ergänzen.
- Datenbankintegration: Angebote in PostgreSQL speichern, um Preisentwicklungen zu verfolgen, den Markt über Zeit zu analysieren und weniger von Third-Party-APIs abhängig zu sein.
- Full-Stack-Testing: Eine Frontend-Testsuite mit Jest und React Testing Library ergänzen, plus End-to-End-Tests mit Cypress oder Playwright.
- UI/UX-Polish: Features wie Pagination, Theme Switcher und weitere Verbesserungen auf Basis von Nutzerfeedback hinzufügen.
Bekannte Eigenheiten & Überlegungen
Jetzt zum weniger spaßigen Teil. Natürlich gibt es Stellen, die nicht komplett perfekt sind. Man könnte sie mit mehr Zeit lösen, aber gemessen am Umfang der Challenge hielt ich sie für akzeptable Trade-offs. Man sollte sie trotzdem kennen.
- Kleine visuelle Macken: Gelegentlich sieht man vielleicht ein Flackern in der UI, etwa in der Statusleiste. Das ist oberflächlich und beeinträchtigt die Funktion nicht.
- Frontend-Modularität: Einige Frontend-Komponenten könnten noch weiter aufgeteilt werden. Die aktuelle Struktur ist robust, aber es gibt immer Raum für mehr Feinschliff.
- Google Places API-Version: Die Browserkonsole könnte ein Update des Google Places SDK vorschlagen. Die aktuelle Version wird vollständig unterstützt und funktioniert einwandfrei.
- Google Maps SDK-Meldungen: Eine harmlose CORS-bezogene Warnung vom Google Maps SDK kann in der Konsole auftauchen. Es ist eine bekannte Diagnosemeldung und beeinflusst nichts.
- Frontend-Entwicklung: Mir ist aufgefallen, dass meine Frontend-Skills zwar für die Challenge gereicht haben, mir aber ein paar Dinge fehlten. Oft kannte ich einfache Lösungen in Next.js für Probleme nicht, auf die ich gestoßen bin, was mich zu überkomplizierten Lösungen brachte, die eigentlich eine Zeile hätten sein können. Das hat auch meinen Codestil etwas verschlechtert. Ich bin mit der Architektur und Optik des Frontend-Codes nicht ganz zufrieden. Allerdings bin ich relativ neu in Frontend und Next.js. Das ist definitiv ein Bereich, in dem ich wachsen kann, und dieses Projekt war perfekt dafür. Was ich hier gelernt habe, fließt in meine künftigen Projekte ein, vieles davon bereits jetzt.
Abschließende Gedanken
BetterSurf zu bauen war ein Marathon, kein Sprint. Es war eine rigorose Übung darin, Komplexität zu managen, für Fehler zu designen und eine User Experience zu polieren. Es hat mein Vertrauen gestärkt, eine produktionsreife Anwendung von Grund auf zu entwerfen und zu bauen. Ich bin unglaublich dankbar für das GenDev-Stipendium und freue mich darauf, diese Learnings auf die nächste große Challenge anzuwenden. Ein riesiges Shoutout an das gesamte CHECK24-Team hinter dieser Challenge, das allen Teilnehmenden ermöglicht hat, ihre Fähigkeiten zu testen und zu beweisen.
BetterSurf hat meine technischen und problemlösenden Fähigkeiten an ihre Grenzen gebracht. Im Laufe dieses Projekts habe ich meine Expertise in API-Integration, Resilience Engineering, Real-Time Data Streaming und skalierbarem Cloud Deployment vertieft. Ich habe meine Fähigkeit geschärft, unter engen Constraints robuste Architekturen zu entwerfen, mich schnell an unvorhersehbare Third-Party-Systeme anzupassen und trotz Backend-Komplexität eine nahtlose User Experience zu liefern. Diese Erfahrung hat nicht nur gezeigt, dass ich produktionsreife Systeme von Grund auf bauen kann, sondern auch mein Selbstvertrauen als Full-Stack Engineer gestärkt, der bereit ist, komplexe Herausforderungen mit hohem Impact anzugehen.
Mehr dazu
Wenn du mehr über dieses Projekt lesen möchtest, schau gern in mein GitHub Repository. Dort findest du den vollständigen Code in seiner ganzen, manchmal fragwürdigen, Pracht.
